Stable-V2A: Synthesis of Synchronized Sound Effects with Temporal and Semantic Controls
Gramaccioni R.F., Marinoni C., Postolache E., Comunità M., Cosmo L., Reiss J.D., Comminiello D. - arXiv preprint arXiv:2412.15023
Abstract
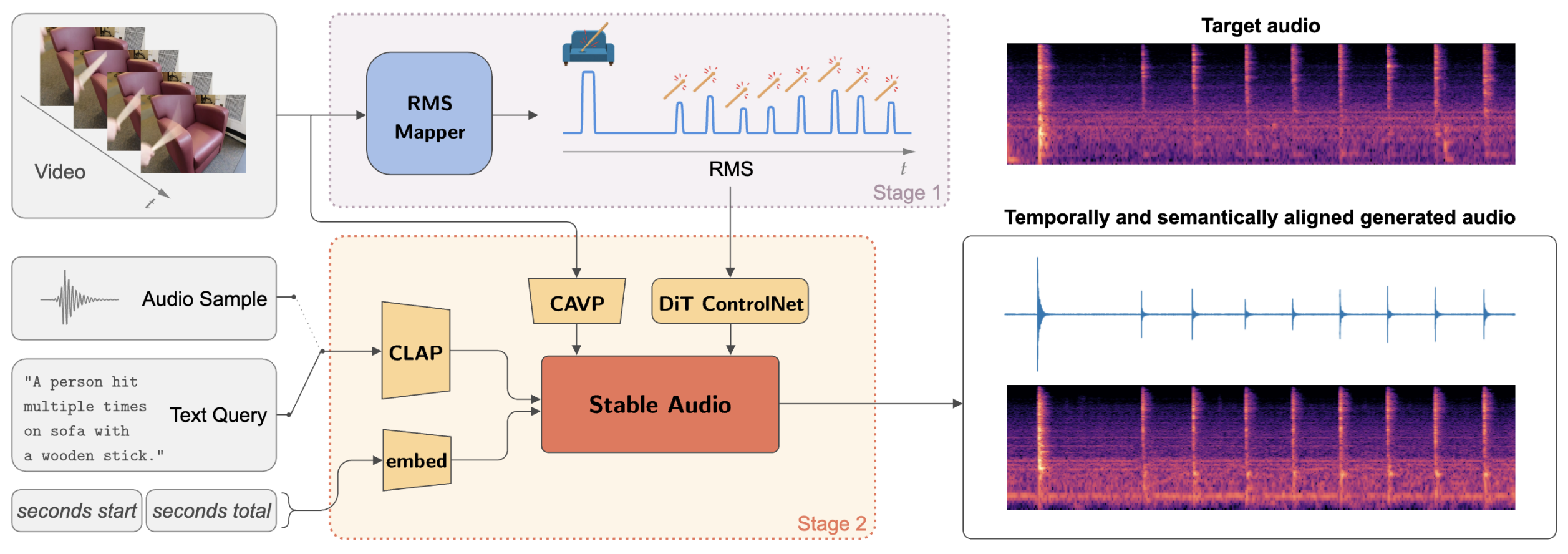
Sound designers and Foley artists usually sonorize a scene, such as from a movie or video game, by manually annotating and sonorizing each action of interest in the video. In our case, the intent is to leave full creative control to sound designers with a tool that allows them to bypass the more repetitive parts of their work, thus being able to focus on the creative aspects of sound production. We achieve this presenting Stable-V2A, a two-stage model consisting of: an RMS-Mapper that estimates an envelope representative of the audio characteristics associated with the input video; and Stable-Foley, a diffusion model based on Stable Audio Open that generates audio semantically and temporally aligned with the target video. Temporal alignment is guaranteed by the use of the envelope as a ControlNet input, while semantic alignment is achieved through the use of sound representations chosen by the designer as cross-attention conditioning of the diffusion process. We train and test our model on Greatest Hits, a dataset commonly used to evaluate V2A models. In addition, to test our model on a case study of interest, we introduce Walking The Maps, a dataset of videos extracted from video games depicting animated characters walking in different locations. Samples and code available on our demo page at https://ispamm.github.io/Stable-V2A.
Resources
- Paper: https://arxiv.org/abs/2412.15023
- Webpage: https://ispamm.github.io/Stable-V2A/
Citation
Gramaccioni R.F., Marinoni C., Postolache E., Comunità M., Cosmo L., Reiss J.D., Comminiello D. "Stable-V2A: Synthesis of Synchronized Sound Effects with Temporal and Semantic Controls" - arXiv preprint arXiv:2412.15023.